

機械学習の分野において、自己教師あり学習と教師なし学習の違いについては混同されることも多く、不安を抱かれる方も多いのではないでしょうか。本記事では、自己教師あり学習と教師なし学習の異なるアプローチや特徴を分かりやすく解説し、違いを明確に理解することを目指します。自己教師あり学習と教師なし学習の違いを日常生活での物事に例えてイメージで理解していきます。それでは、さっそく解説していきますので、一緒に学んでいきましょう。
自己教師あり学習とは?
まず、自己教師あり学習について解説していきましょう。
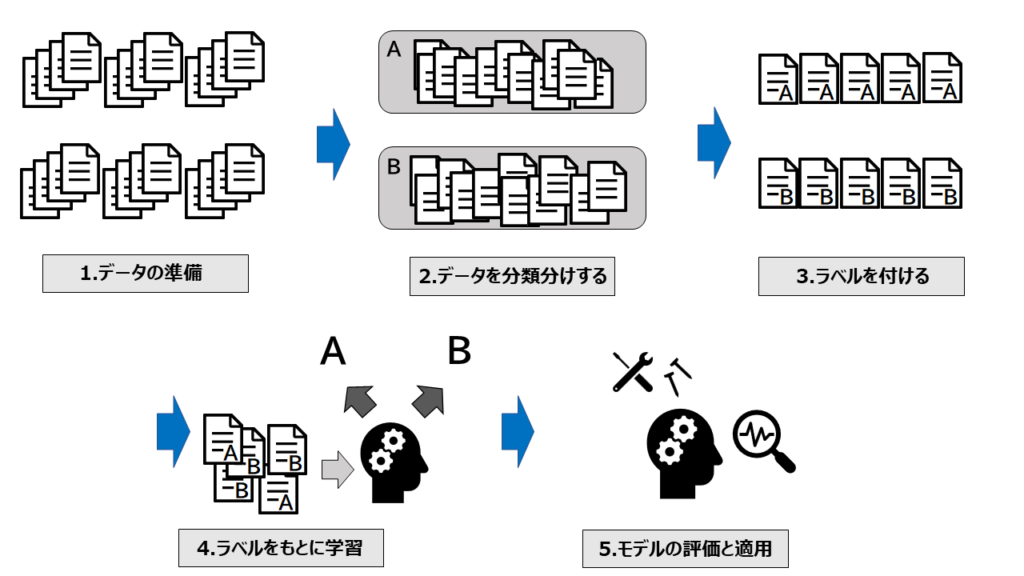
教師あり学習とついていますが、自己教師あり学習は教師データやラベルが無いデータでも学習することができます。自己教師あり学習の立ち位置としては、教師あり学習と教師なし学習の中間的な手法と言えます。
自己教師あり学習は、ラベルの付いた教師データを用意することが難しい場合に、データ自体から学習を進める手法であり、教師なし学習に近い性質を持ちます。しかし、自己教師あり学習では、予測結果を新たなラベルとして再利用することで、間接的に教師データを生成し、モデルの学習を進めます。そのため、教師あり学習にも近い性質を持っています。
教師なし学習とは?
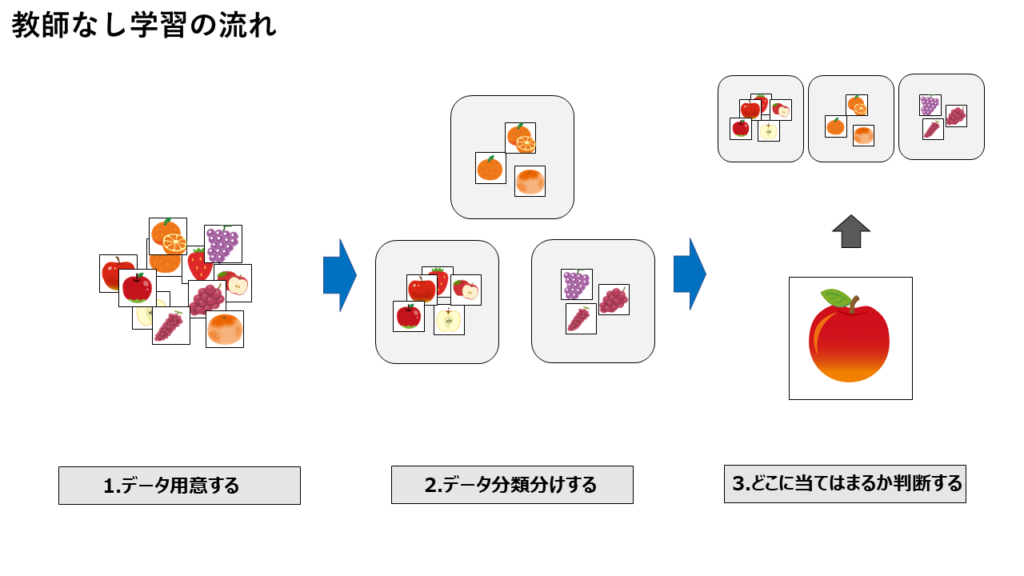
教師なし学習は、データに対するラベル付けがされていない状況で、データ自体の特徴や構造を解析し、知識の発見やデータの理解を行う手法です。教師なし学習では、事前に用意されたラベルを用いずに、データ自体が持つ情報や構造を学習し、データをグループ化したり、異常検出を行ったり、データの次元削減を行ったりすることができます。
教師なし学習の代表的な手法には、クラスタリング、次元削減、異常検出、生成モデルなどがあります。クラスタリングは、似た特徴を持つデータをグループ化する手法であり、データのグループ分けや類似性の発見に利用されます。次元削減は、高次元のデータを低次元に変換する手法であり、データの可視化や次元の削減に利用されます。異常検出は、データの中から異常なデータを検出する手法であり、異常データの検出や異常の発見に利用されます。生成モデルは、データを生成するモデルを学習する手法であり、新たなデータの生成やデータの生成プロセスの解明に利用されます。
教師なし学習は、ラベルが付与されていないデータを扱う際に有用であり、データの解析や知識の発見、データの理解を支援する手法として幅広い応用があります。
自己教師あり学習と教師なし学習の違いは?
ここまで自己教師あり学習と教師なし学習それぞれについて説明してきました。
自己教師あり学習と教師なし学習の共通点と違いをまとめてみます。
2つの学習の共通点
自己教師あり学習と教師なし学習の共通点
・ラベル付けがされていないデータを扱う
両方の手法は、データに対するラベル付けがされていない状況下での学習を行います。つまり、事前に用意された正解ラベルを用いずに、データ自体が持つ情報を学習します。
・データの特徴や構造を解析する
自己教師あり学習、教師なし学習ともに、データ自体の特徴や構造を解析することが共通しています。自己教師あり学習では、生成された教師データの特徴を解析し、モデルを学習します。
一方、教師なし学習では、データ自体のクラスタリング、次元削減、異常検出、生成モデルなどを用いてデータの特徴を解析します。
2つの学習の違い
自己教師あり学習と教師なし学習の違い
・学習のアプローチ
自己教師あり学習では、教師データを生成し、それを用いてモデルを学習するというセミスーパーバイズド学習の手法を用います。一方、教師なし学習では、データ自体の特徴や構造を解析し、データのクラスタリング、次元削減、異常検出、生成モデルなどを用いて知識の発見やデータの理解を行います。
・タスクの目的
自己教師あり学習は、既知のタスクに対してラベル付きデータを生成することで、教師あり学習を近似する手法として利用されます。一方、教師なし学習は、データ自体の特徴や構造を解析し、データのグループ化や次元削減、異常検出、生成モデルなどを通じた知識の発見やデータの理解を目的とします。
・応用分野
自己教師あり学習は、教師あり学習のデータラベルが限られている場合やラベル付けが困難な場合に有効です。一方、教師なし学習は、ラベル付けがされていないデータの解析や知識の発見、データの理解を支援する手法として幅広い応用があります。
自己教師あり学習と教師なし学習の違いをイメージで理解しよう!
例1 画像処理
2つの学習方法を画像処理を使って理解してみましょう。りんごを理解する手順の違いを見ていきます。
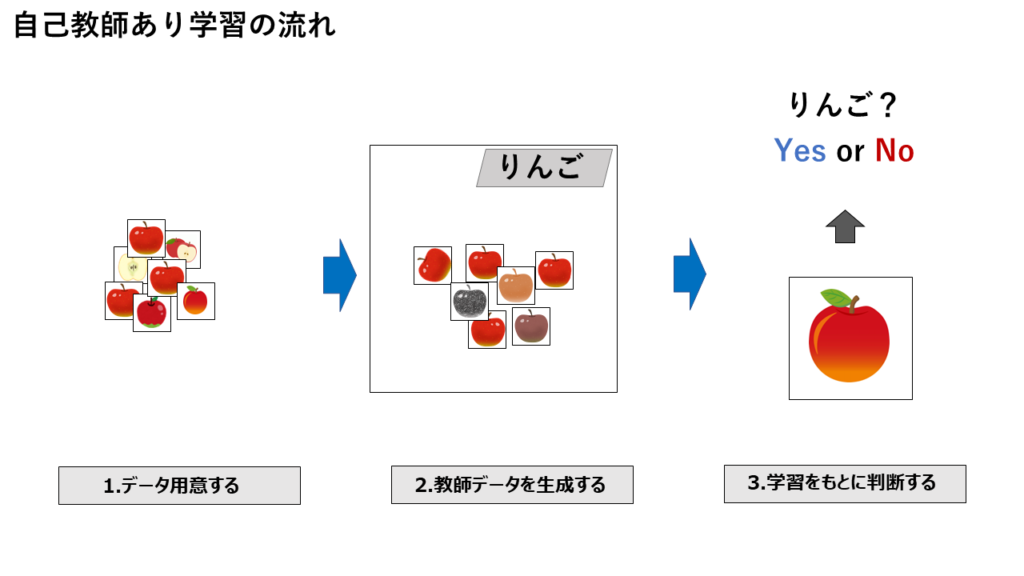
自己教師あり学習は、りんごに関する正解データを用意できない場合でも、生成モデルを用いて教師データを生成します。例えば、りんごの画像を用意し、GAN(Generative Adversarial Networks)を使って、似たようなりんごの画像を生成します。生成された教師データを正解ラベルとして用いることで、モデルがりんごの画像を識別するための特徴を学習します。
一方、教師なし学習は、りんごの画像を含むデータをクラスタリングアルゴリズムを用いてクラスタに分割します。クラスタごとにりんごの画像を解析し、クラスタ内での共通の特徴を抽出します。例えば、りんごの画像に共通して現れる色や形状などの特徴を抽出します。抽出された特徴を用いて、りんごの画像を識別するモデルを学習します。クラスタごとに共通の特徴を用いることで、モデルがりんごの画像を識別するための特徴を学習します。
例2 自動運転車
続いて自動運転車をれいに挙げて説明してみましょう。
自己教師あり学習は、自動運転車が自分自身で運転を学ぶようなイメージです。最初に人間の運転手が運転をし、その際に得られるセンサーデータを使って車自体が予測を行い、自分自身を教師として学習を進めます。運転手が曲を曲がる際にブレーキを踏んだ場合、車はそれを予測し、次回同じ状況での適切なブレーキ操作を学習することができます。
一方、教師なし学習は、自動運転車が運転手の操作を受けずに自らのセンサーデータを解析し、道路の特徴や他の車両との関係性を見つけ出すイメージです。センサーデータを用いてクラスタリングを行い、道路の車線や車両の位置関係を自動的に学習することができます。
まとめ
自己教師あり学習は、データのラベルが不完全または存在しない場合に有望な機械学習手法として注目されています。今後の展望としては、以下のようなポイントが考えられます。
- 自己生成モデルの性能向上: 自己教師あり学習では生成モデルを活用して未ラベルデータを生成し、それを用いてモデルを更新します。生成モデルの性能向上が課題であり、より高品質なデータ生成や過学習の抑制が求められます。
- データの活用範囲の拡大: 現在は画像やテキストなどの領域での自己教師あり学習が主流ですが、今後は音声や動画、センサーデータなど、さまざまなデータに対しての適用範囲が拡大されることが期待されます。
- ラベル付きデータの利用効率化: 自己教師あり学習では初期のラベル付きデータを必要としますが、その数を減らすための手法や、ラベルの高品質化のための方法が今後も研究されるでしょう。
- ドメイン適応や転移学習への応用: 自己教師あり学習はドメイン適応や転移学習との組み合わせにより、異なるドメインやタスク間での学習を実現する手法として期待されています。異なるドメインやタスク間でのラベルの共有や転移が可能な自己教師あり学習の手法の開発が今後の課題となります。
- セキュリティや倫理面の考慮: 自己教師あり学習は大量の未ラベルデータを活用するため、データのプライバシーやセキュリティ、倫理面の問題にも注目が必要です。データの収集や使用において倫理的な考慮を加えるためのガイドラインやルールの整備が求められます。
これらの展望を考慮しながら、自己教師あり学習は今後も進化し、新たな応用分野や問題の解決に向けて発展していくことが期待されます。


コメント